
前言
本次学习基于jdk1.8源码进行讨论。
1、基础结构
先看一眼ArrayList都和哪些 类 和 接口 有关系:
从类的开头可以看出,ArrayList继承了一个抽象列表AbstractList ,并且实现了List、RandomAccess、Cloneable、Serializable这四个接口,尽管AbstractList已实现List接口,但ArrayList的显式声明增强了代码的可读性。
List:列表的基础定义,只有具有
List中定义的特征的类,才能被称为是一个列表,这里用于表明ArrayList类是符合基本列表定义的。RandomAccess:用于表明
ArrayList类支持高效的随机访问(如list.get(index)的场景)。这里比较明显的例子就是和LinkedList的对比,LinkedList并没有实现RandomAccess接口,在使用for(int i=0; i<list.size(); i++){list.get(i);}的方式进行遍历时,ArrayList的效率碾压LinkedList。并且ArrayList通过迭代器Iterator<T>遍历和通过for循环遍历时也能发现,后者效率略高于前者;但使用LinkedList测试时则恰恰相反,通过迭代器顺序访问的效率显著高于传统for循环随机访问。观察LinkedList源码后也发现其并没有实现RandomAccess接口,符合接口定义与实际情况。Cloneable:用于表明
ArrayList类是可以被克隆的,虽然这个接口中也没有任何方法,但实现后一般需要重写父类Object中的clone方法。在ArrayList中,重写clone时使用了super.clone()得到了一个浅拷贝的Object类型的克隆对象,接着使用数组工具类中的Arrays.copyOf()方法将数组内容进行了拷贝,并赋值给浅克隆对象的elementData成员,最后重置操作次数modCount并返回克隆后的数组对象Object类型以完成克隆操作。Serializable:表明
ArrayList类是可序列化和反序列化的。序列化是将Java对象扁平化的一个过程,常见的是将Java对象序列化成字节流,这通常是为了方便网络传输、数据存储等,反序列化则是将字节流反向转换成Java对象的过程。关于Serializable接口,直观的体现是在使用ObjectOutputStream对象时,如果要使用它下面的write方法或者ObjectInputStream下的read方法,则需要对应的类实现Serializable接口,否则会抛出java.io.NotSerializableException异常。AbstractList:抽象类,用于提供最小化的具有
List特征的骨架方法。继承AbstractList类后,ArrayList就已经算是一个合格的列表了,但由于AbstractList只是最小化实现,其中存在少量的抽象方法(如abstract public E get(int index))以及默认不可用的实现(如public E set(int index, E element) { throw new UnsupportedOperationException(); }),所以在ArrayList中都对它们进行了重写。PS:关于为什么既有抽象方法又有默认报错实现,AI的解释是为了体现对不同操作强制性与可选性的权衡,读取元素get(int index)操作对所有的列表(无论是否可变)都必须要支持,否则无法称为“列表”;而修改元素E set(int index, E element)(写操作)是可选操作,对于某些不可变列表(如Collections.unmodifiableList)或某些特殊结构的列表(如基于只读数据源的列表),它们是不支持修改的。此外也是为了遵循接口的“可选操作”规范和减少子类冗余代码。
2、构造函数
2.1 无参构造
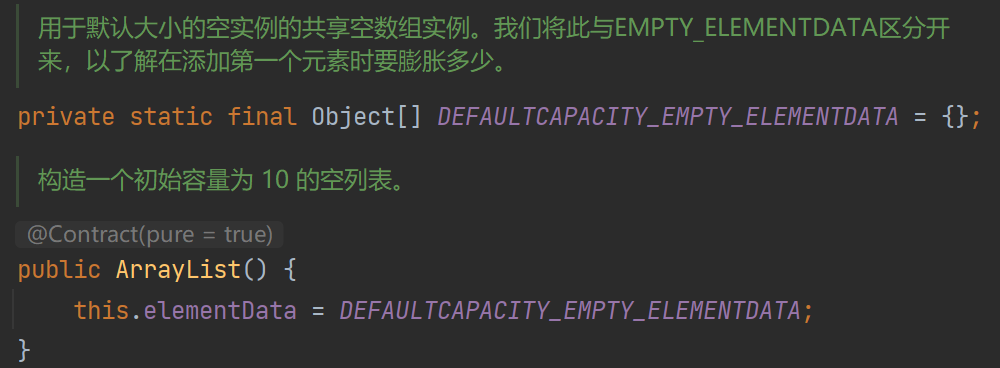
为了方便观察,我用PS将要用到的一些常量和方法拼在一张图上了,实际观察源码这些变量的位置会有所差别。
这里注释说是初始化一个长度为10的空列表,但实际上DEFAULTCAPACITY_EMPTY_ELEMENTDATA是一个长度为0的空列表。真正初始化的操作其实是在第一次向数组中添加元素时,通过调用ensureCapacityInternal方法完成的,具体在讲add方法时详细讲解。
2.2 参数为int的构造函数
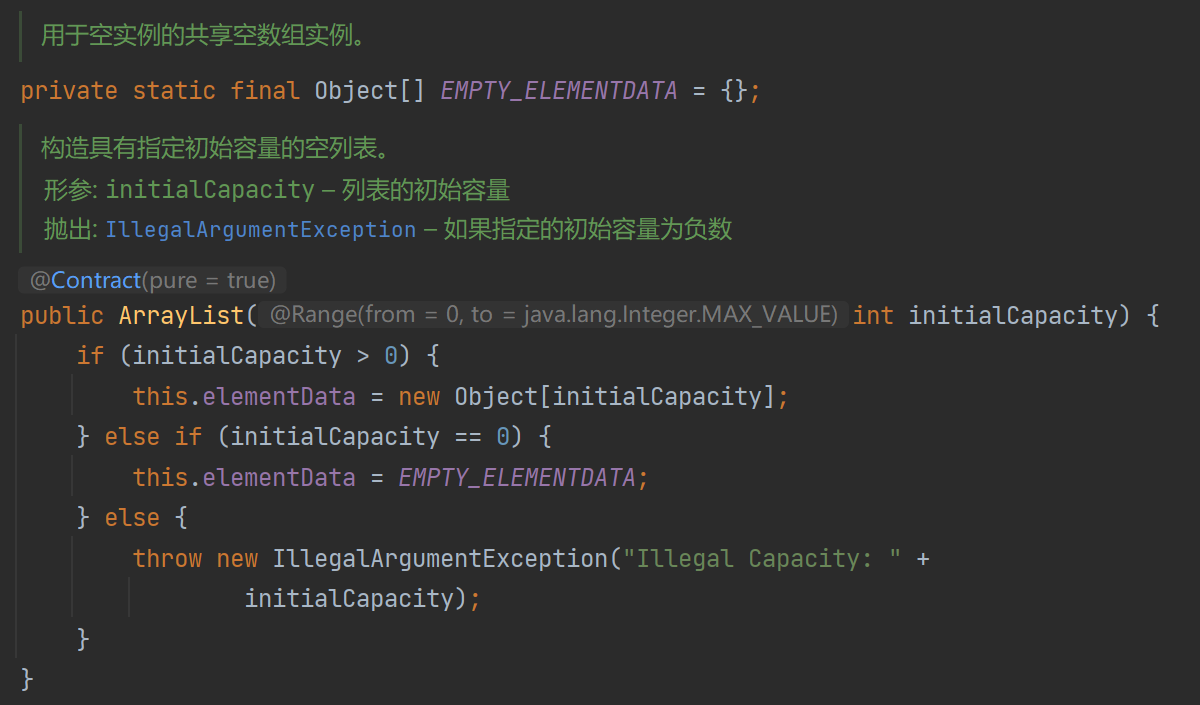
指定底层动态数组初始容量的构造函数,可以看到它校验了初始化长度,大于0时初始化一个长度为initialCapacity的数组,等于0时直接赋值为一个默认为空的数组,最后小于0则参数不正确,抛出IllegalArgumentException异常。
2.3 参数为单例集合类的构造函数
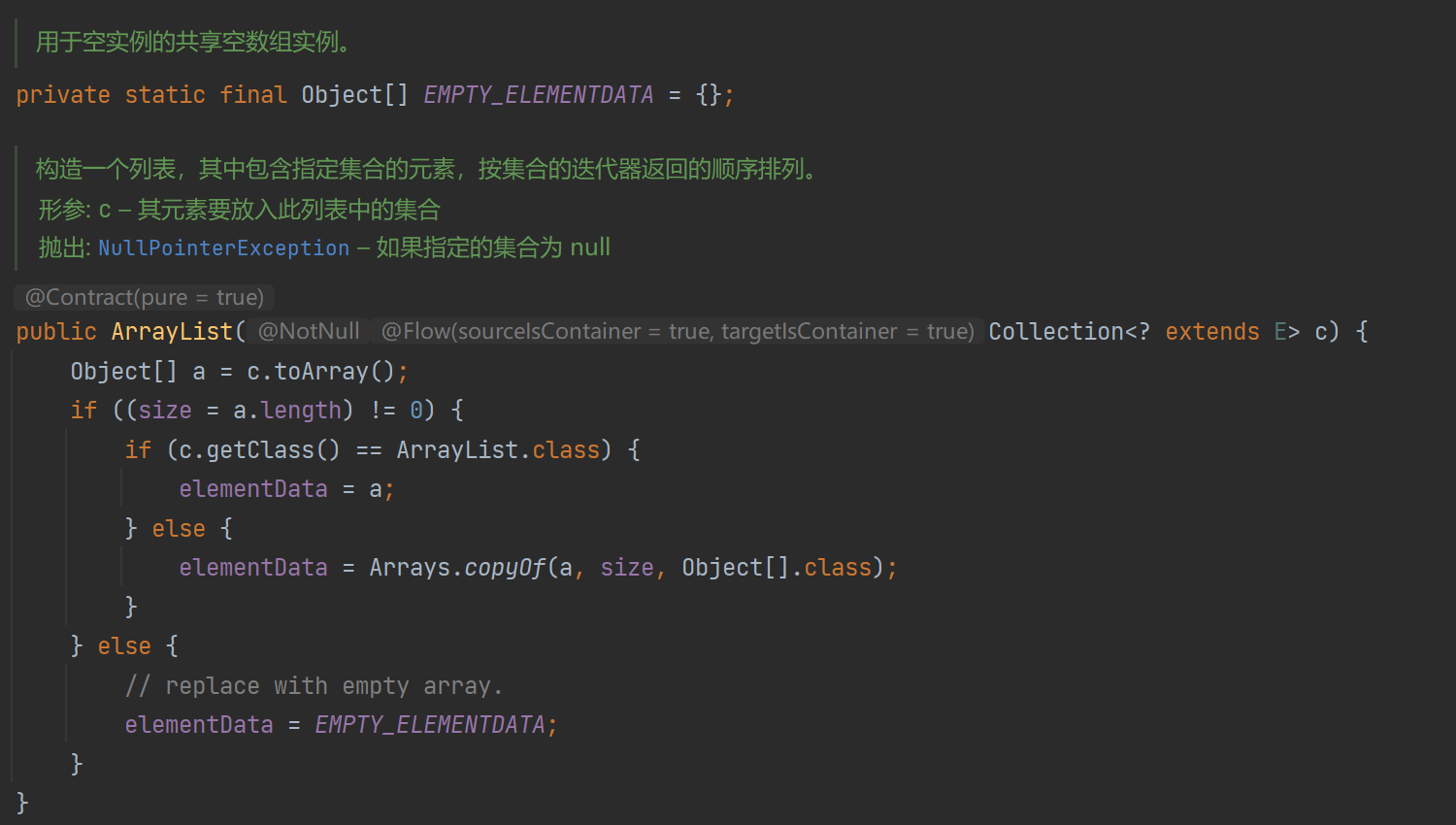
这里先调用了传入集合的toArray方法,得到了一个Object类型的对象数组,这里的toArray可能来源于不同的实现,因为在ArrayList继承的AbstractList中,AbstractList实现了接口List,而List则需要实现Collection接口,这里贴一张ArrayList的类图:
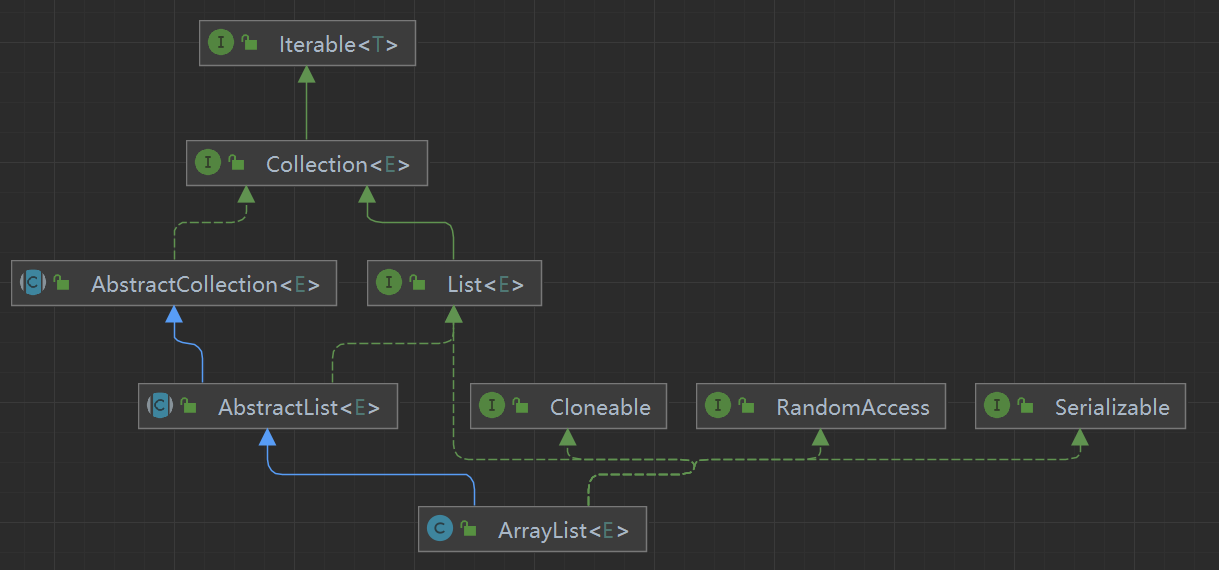
相应的这里调用的toArray方法是定义在Collection接口中的,会根据传入参数c的类型自动选择,比如c是ArrayList时,会使用Arrays.copyOf方法,其底层是使用的操作系统提供的相应方法进行数组复制。
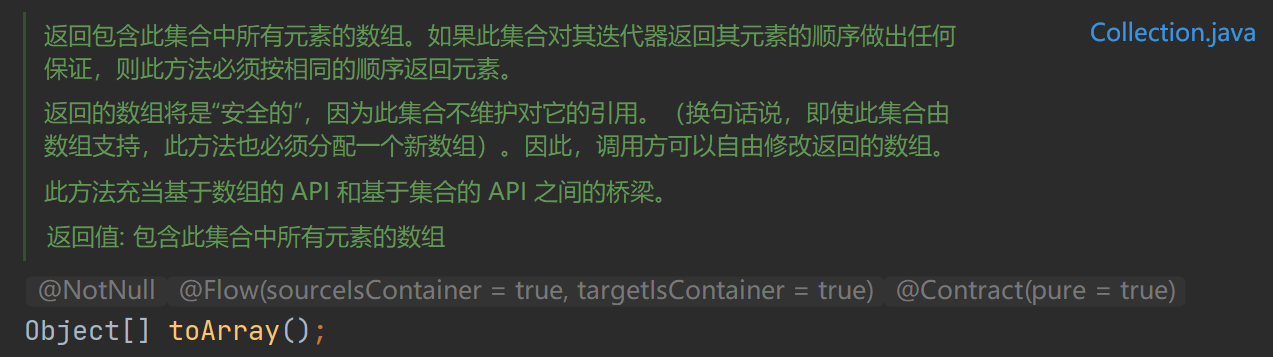
这里只讨论ArrayList的toArray方法:
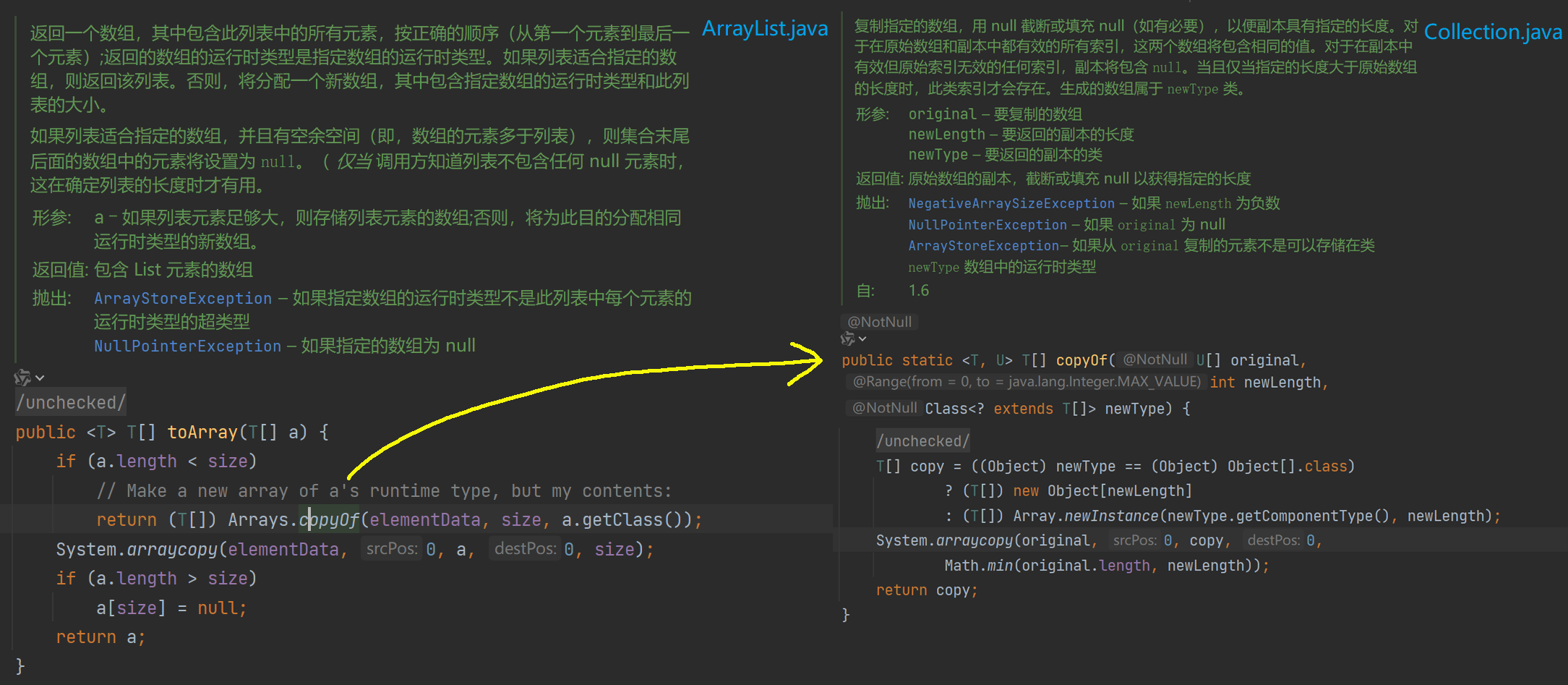
可以看到,这里底层本质上都是调用的操作系统层级的数组复制。
内容复制完成后得到数组Object[] a = c.toArray();,接着判断数组长度是否为0,为0则直接使用预设的空元素数组EMPTY_ELEMENTDATA,不为空则看数组类型是否为ArrayList,是就直接将成员变量elementData赋值为对象数组a,不是则又尝试使用Arrays工具类进行复制元素的操作。
至此,便是ArrayList类的所有构造函数相关内容。
3、add
3.1 add(E e)
这是在使用ArrayList时最常用的添加元素的方法,执行后会往列表的末尾追加一个元素。可以先看看源码,乍一看好像挺简洁的:
事实上也确实很简洁,使用ensureCapacityInternal方法检查是否要进行扩容,接着直接往ArrayList底层装元素的数组中设置就完成了。所以其实弄清楚ensureCapacityInternal做了什么,就能理解ArrayList的动态数组是怎么动的了,那跟进去看看:
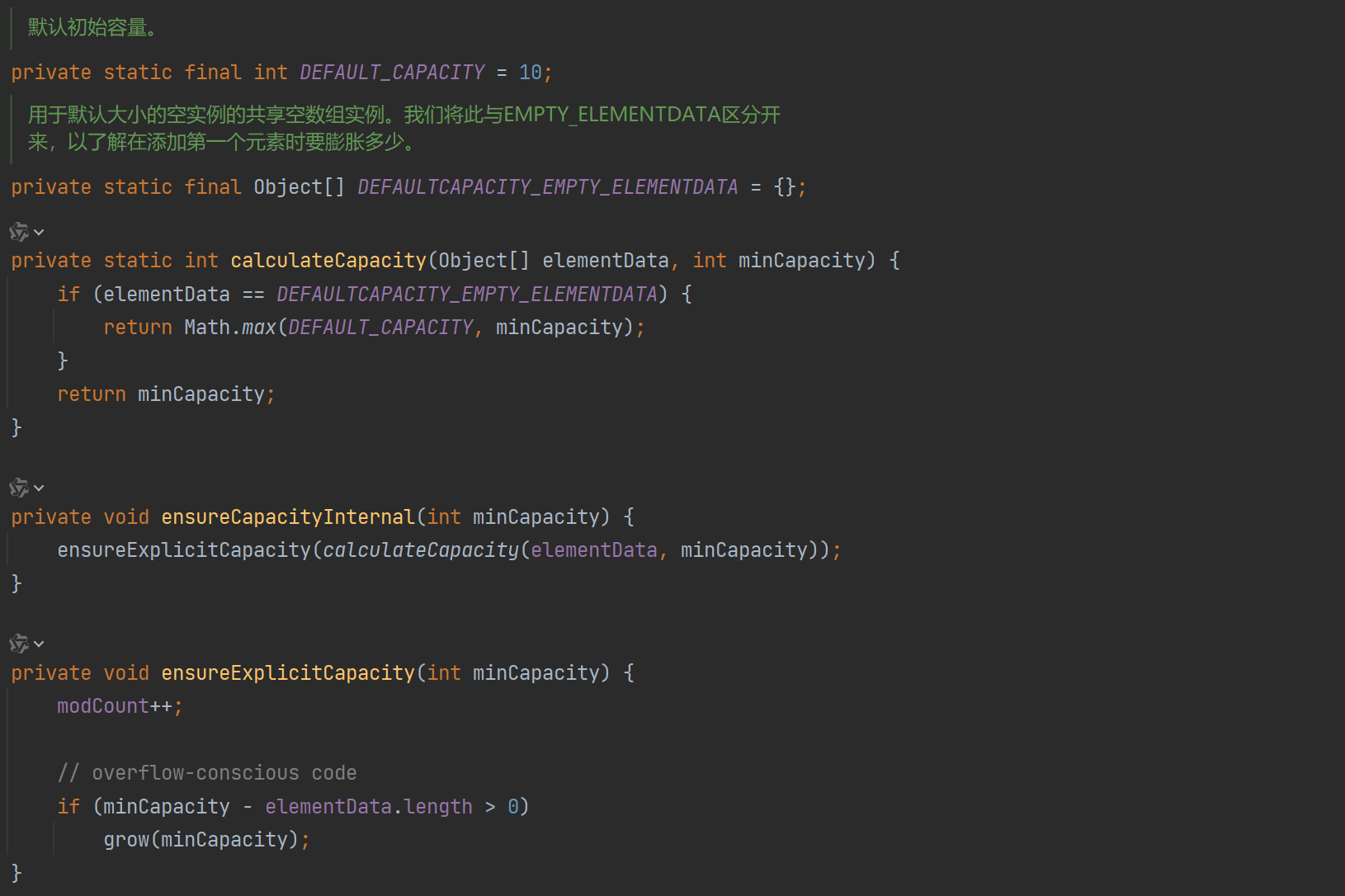
可以看到在ensureCapacityInternal中的扩容过程大概分为三步:①:得到最小操作数;②:需不需要扩容;③:如果需要扩容,那阔多少合适。至于最后扩容相关的操作则被封装在grow方法中。
来看看过程,首先会算一个叫最小容量minCapacity的东西,看当前的数组是否已经初始化,上面讲构造函数时说的初始化一个容量为10的数组就是这里做的。在第一轮添加时,elementData是空数组{}所以calculateCapacity中的if为真,同时传递的minCapacity是size+1也就是0+1 = 1,经过Math.max(10, 1)的运算得出最小操作数就是10,而后续添加时,由于elementData不是空数组,就会直接返回传入的操作数,也就是size+1。
接着由ensureExplicitCapacity函数检查是否要扩容,也就是if (minCapacity - elementData.length > 0)东西,第一次添加时是if(10 - 0 > 0)于是触发扩容grow,第二次是if(10 - 10 > 0)不触发库容...直到下一次触发扩容时调用grow。
那接下来看看grow都做了什么:
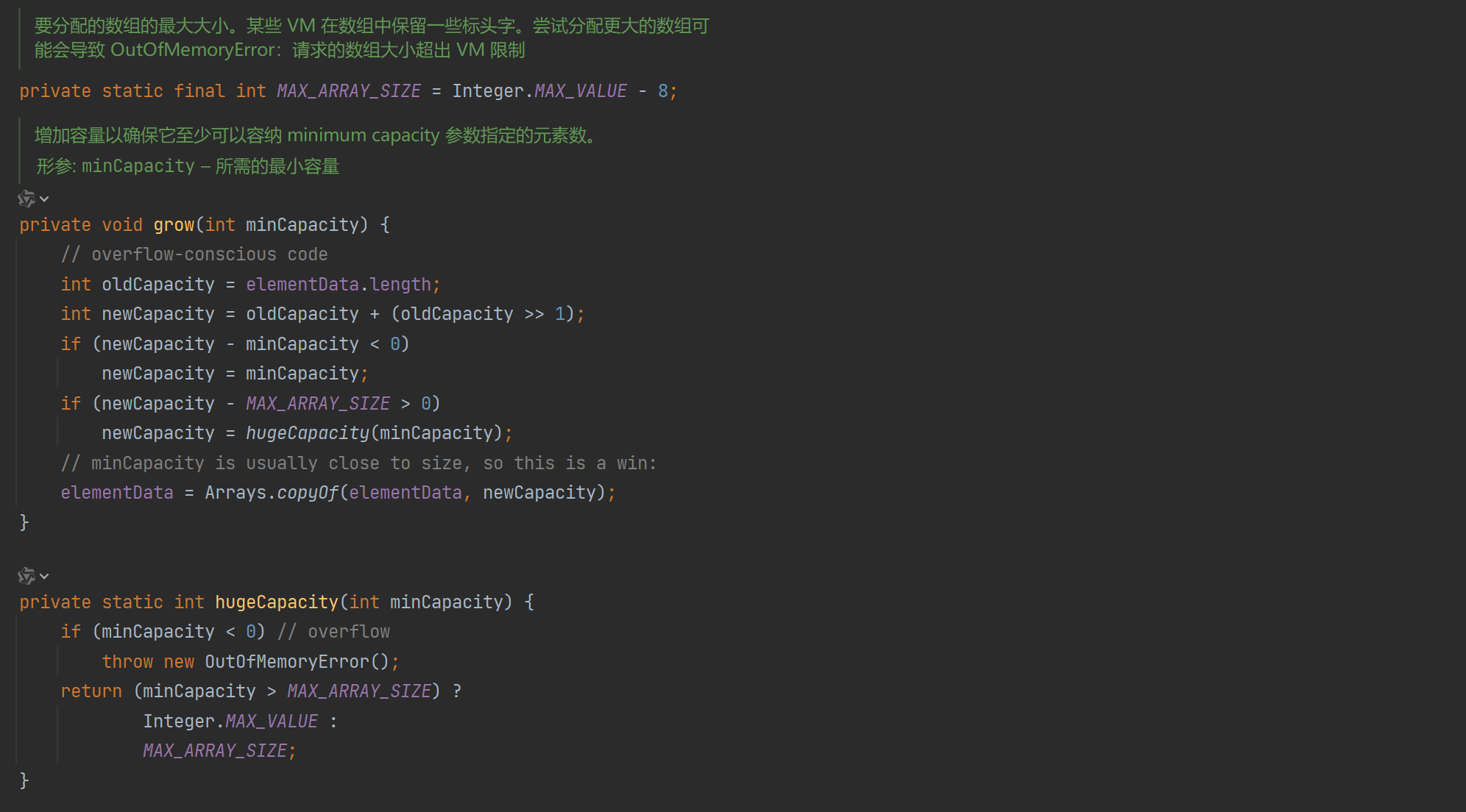
可以看到grow函数的前半段校验了一下参数,这里oldCapacity >> 1的意思可以理解÷2操作,向右移几位就是除2的几次方,同理向左移就是乘。接着处理了一下特殊情况(超大数组),然后使用数组工具类的Arrays.copyOf方法进行扩容操作。这个copyOf再往后的实现就是基于本地代码实现了,比如这个System.arraycopy方法就用了native关键字进行修饰,那些就不管了,到此为止。
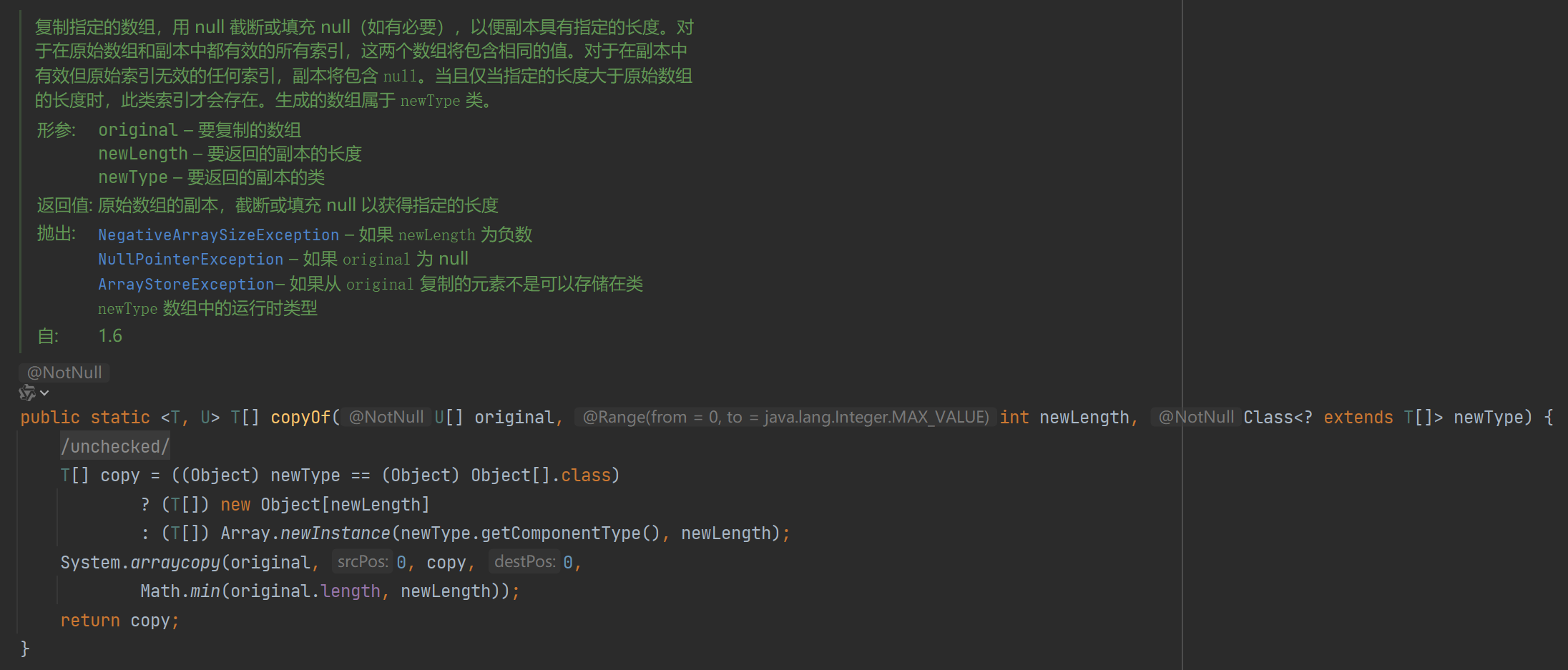
3.2 add(int index, E element)
这是add方法的一个重载,可以在列表的指定位置添加元素。
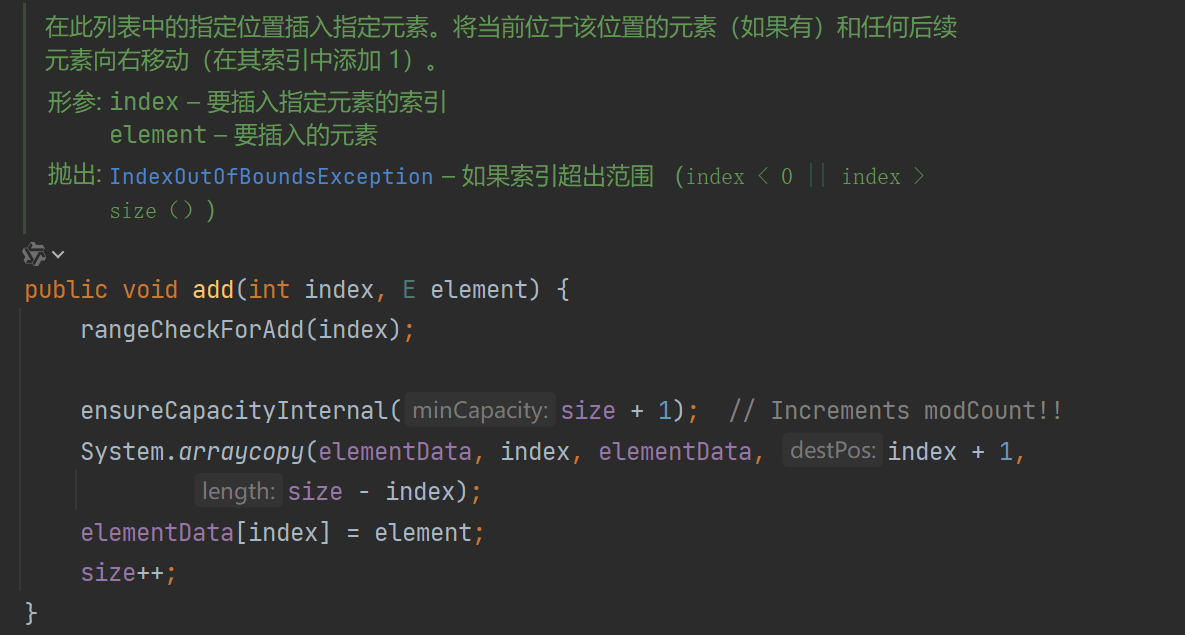
可以看到整体上还是和add(E e)方法比较像的,除了多了个rangeCheckForAdd和数组复制方法System.arraycopy以外。rangeCheckForAdd方法做的事很简单,就是判断了一下index是否越界而已,越界就抛出异常。

而接着调用的ensureCapacityInternal和在add(E e)方法中的用法作用都是完全一致的,判断是否要扩容,扩多少合适。
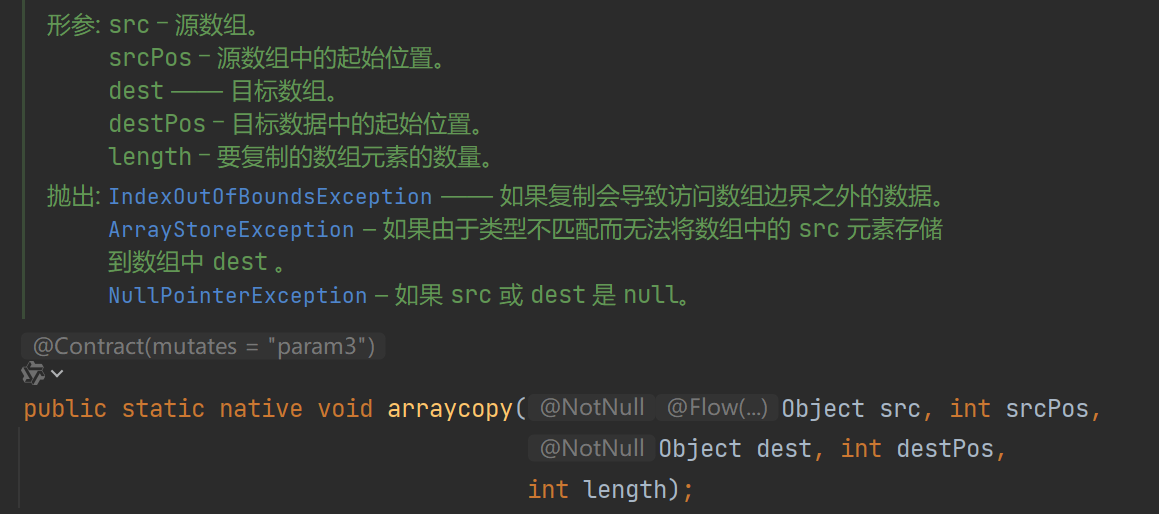
接着,使用了System.arraycopy进行数组数据的复制移动,这个方法的注释还蛮长的,这里就只是看一下它的各个参数都是什么意思,感兴趣的朋友请自行阅读源码。
那结合起来看,在add方法中调用arraycopy就是将elementData数组中从第index位开始到最后的所有数据都向后移一位,这样一来原本index的位置就空出来了。最后直接使用elementData[index] = element设置数据,然后size++就完成了向指定位置添加的操作。
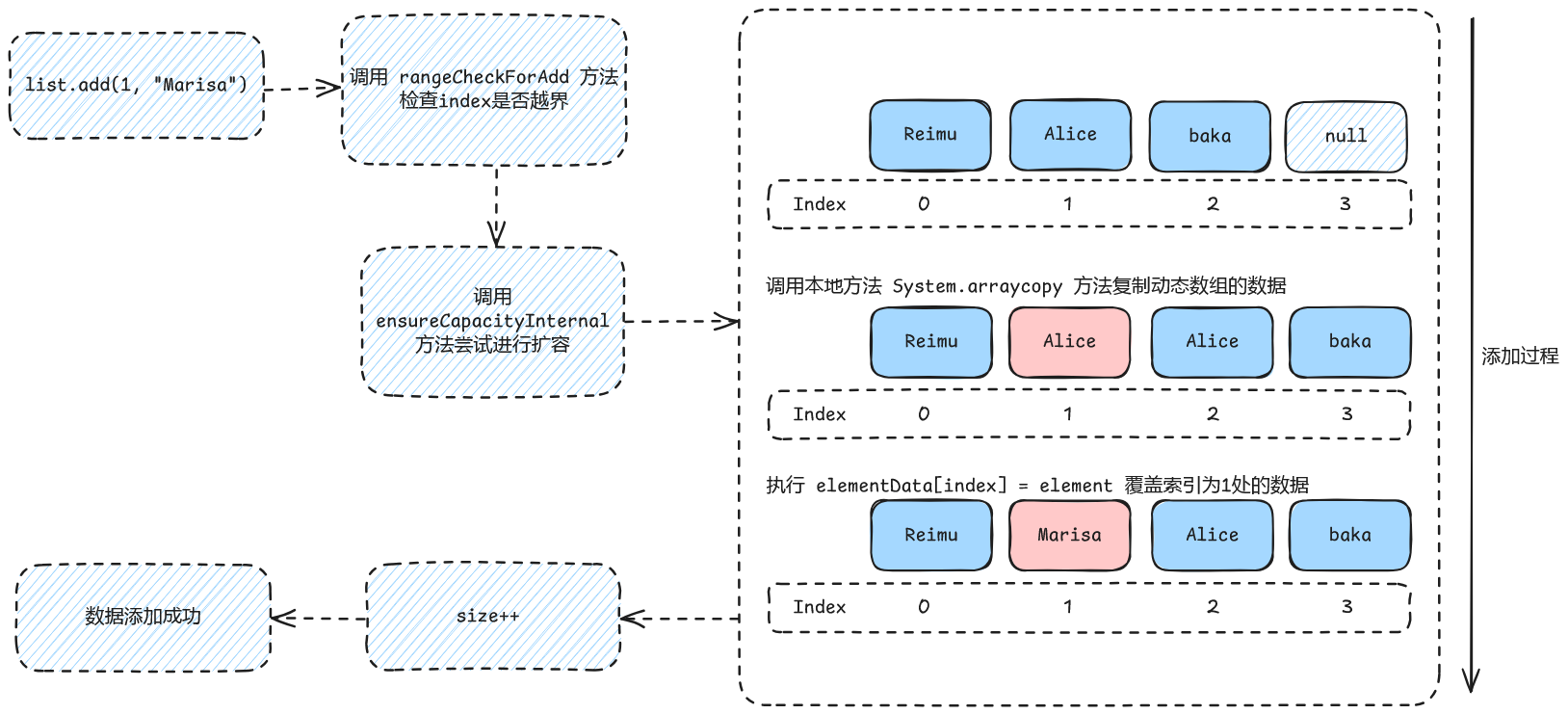
其实这样做效率并不是很高,不过这也符合ArrayList的特性:操作列表元素比较耗时O(n),但查询列表元素却很快O(1)。
3.3 addAll(Collection<? extends E> c)
按照指定集合迭代器iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。来看一眼源码:
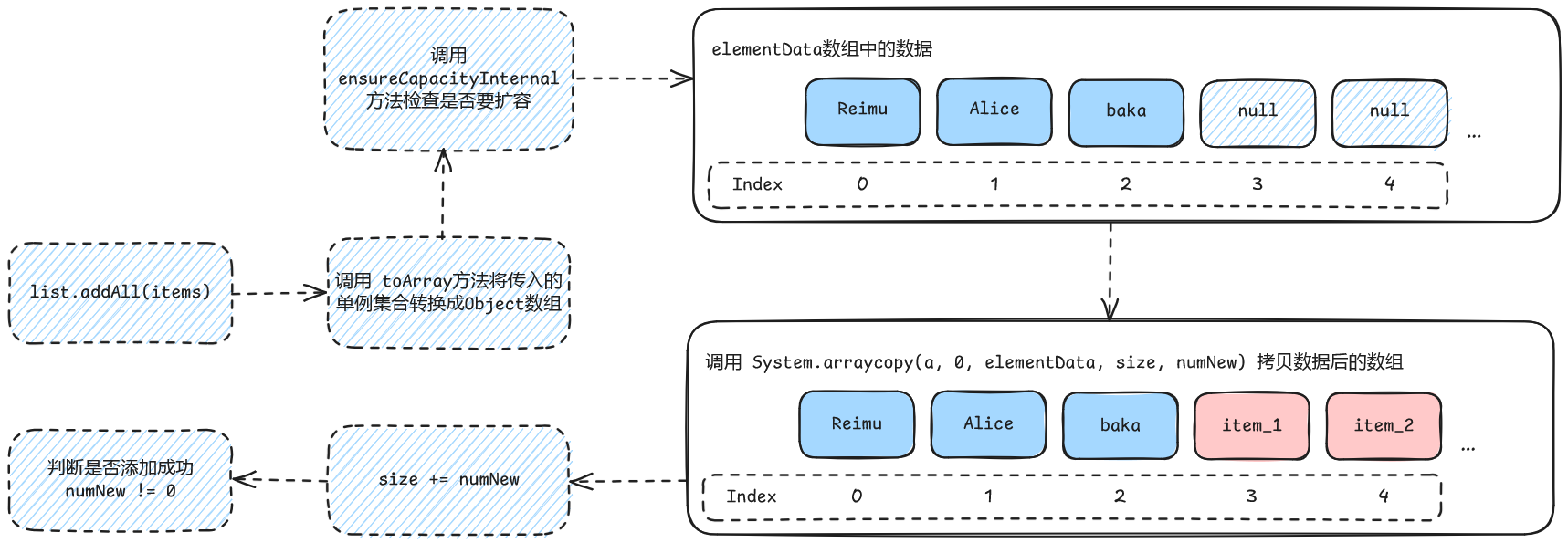
可以看到这里的流程还是很简单的,将传入的单例集合通过其自身的toArray方法转换成数组,接着判断是否需要进行扩容,然后调用数组复制方法把新数组的全部追加到elementData的末尾,最后更新此列表中数组的长度。
3.4 addAll(int index, Collection<? extends E> c)
将指定列表中的所有元素插入到此列表中,从指定的位置开始。这也是最后一个添加相关的方法,直接上源码:
可以看到相比于直接追加到末尾,添加到指定位置的方法会稍微复杂一点。首先第一步还是先rangeCheckForAdd方法校验index是否越界,接着将待添加的集合转换为Object类型的数组,然后判断当前这次操作是否需要扩容。之后算了一个叫numMoved的东西,如果index = size了说明就是在往数组的末尾追加元素,此时就等同于addAll(Collection<? extends E> c);如果index小于size,就说明是在往数组的中途插入元素,那就要将数组中的从index开始到结束的元素依次往后挪动a.length位,而第一个if中的System.arraycopy(elementData, index, elementData, index + numNew, numMoved)就是在做这个事情,将elementData数组中从第index位开始的数据拷贝到elementData的index + numNew位置。而再往后的System.arraycopy就只是将新数组的元素按照迭代器Iterator提供的顺序放到elementData的index处。这便是添加这个addAll方法所作的事情。
.png)
4、get
用于获取列表中指定下标处的元素的方法,ArrayList中只有一个暴露出来的获取元素的方E get(int index)。它在实现上可以说是很简单,先校验下标是否越界,接着从数组中取出对应下标的元素;由于数组在堆内存中是连续的,因此这个过程是非常快的,时间复杂度是O(1)。
原理上基本一看源码就能明白是怎么回事。

5、set
按照指定下标修改元素的方法,实现上也是非常简单,首先检查下标是否越界,接着直接按照给定的下标覆盖相应的元素。值得注意的是,set方法的返回值是被替换前的元素,这是因为List接口明确规定了set方法需返回旧元素。
6、remove
从指定列表中删除一部分元素的操作。
6.1 remove(int index)
这一个方法是从按照索引下标的方式删除对应下标的元素。源码上来说也不是很复杂,首先还是一样的,检查索引下标是否越界;接着操作次数加一;然后取出了被删掉的那个元素准备在方法执行完成后返回,到目前为止和set操作都挺像的。
接下来算的这个numMoved其实就是删掉这个元素后,会影响到的元素的起始下标,比如列表中有5个元素,我删掉了下标为1处的元素,此时会影响到下标2、3、4的元素,因为1被删了,那所有在1后面的元素就都得向前移动一位。而如果删除的是数组末尾的元素(下标为4),此时就不用移动数组,因为4后面没有元素了,直接将数组中对应的下标置空就行了。
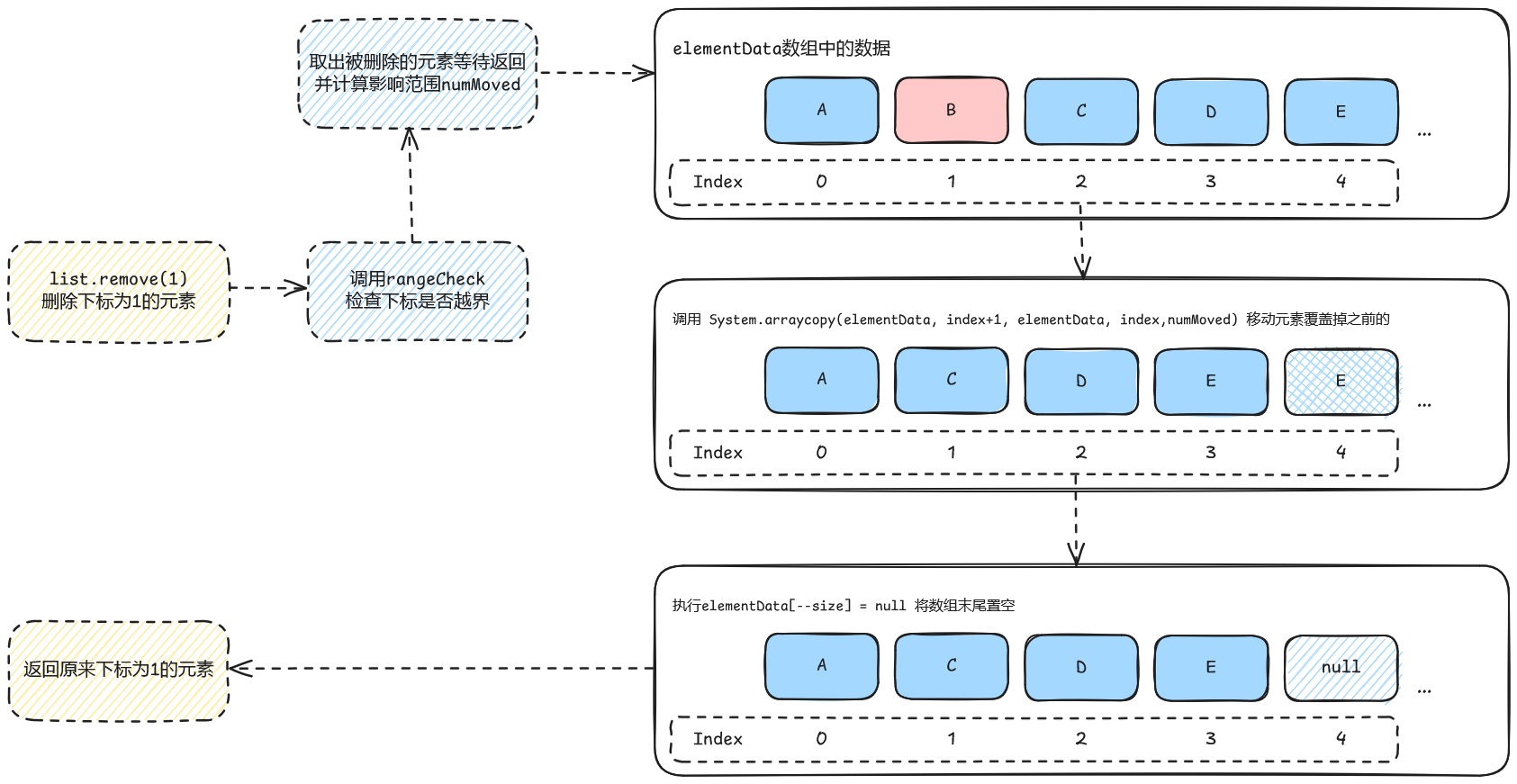
上面就很清晰的展示了通过下标删除元素的执行流程。
6.2 remove(E element)
根据元素的内容删除第一个满足条件的元素,这里会比直接通过索引下标的方式复杂一点:
可以看到源码中将对象进行了区分,如果传入的是null,则直接使用==运算符进行比较,找到满足条件的元素后使用内部方法fastRemove进行删除,而非空对象则使用的是对象本身的equals方法判断是否相等(equals的默认实现是==,但好处是可以由开发者来定义什么叫相等)。这里删除的本质还是通过复制数组元素的方式,最后通过删除数组末尾的“漏网之鱼”完成remove的操作。
对了,在这里提一个之前看到的挺有趣的面试题:
Integer index = 0;
ArrayList<Integer> list = new ArrayList<>(Arrays.asList(0, 1, 2, 3));
list.remove(0); // 这两个remove走的是同一个吗?为什么?
list.remove(index);
System.out.println(list); // 结果是什么?问:这段代码中的两个remove方法调的是同一个么?为什么?以及代码执行完后list中的内容是什么?
答:不是同一个,list.remove(0)调用的方法是根据索引删除,此时删掉了下标为0的元素0,而list.remove(index)调用的是根据元素删除remove(E element),最终结果是[1, 2, 3]。第一个remove操作list.remove(0)传递的是字面量0,是基本类型int,所以会走索引删除remove(int index);而list.remove(index)传入的是包装类Integer,虽然它后面会自动拆箱,但在调用时它仍然是个对象(值为0),所以会走remove(Object o),按照对象的形式删除,但由于之前通过下标删除时已经将元素0删掉了,此时根据值进行删除会失败,所以结果仍然是[1, 2, 3]。
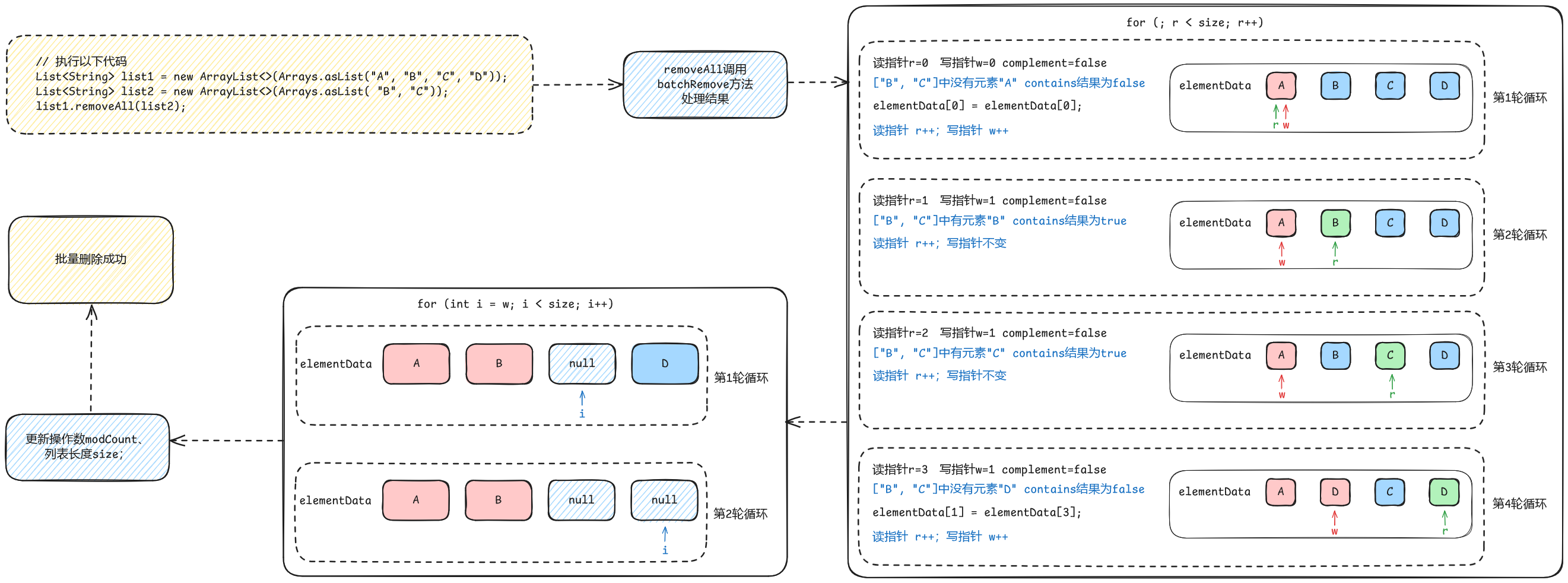
6.3 removeAll(Collection<?> c)
批量删除元素又会更复杂一点:不过最主要的逻辑都被封在了batchRemove函数中:
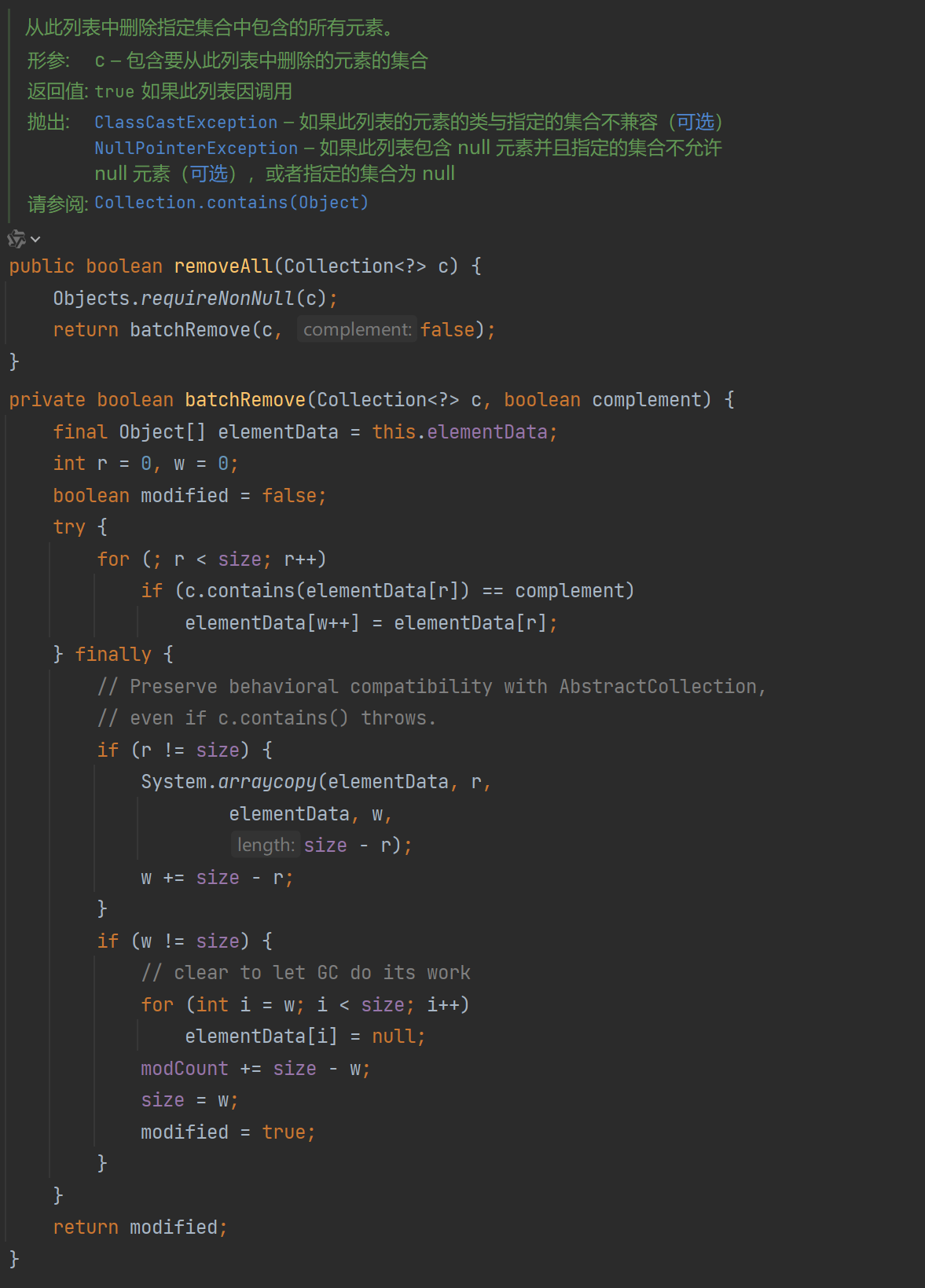
至于为什么要单独抽一个batchRemove出来,其实是为了兼容retainAll方法,retainAll方法用于得到传入集合和此集合的交集。用法上大概是这样:
ArrayList<String> list1 = new ArrayList<>(List.of("A", "B", "C", "D"));
ArrayList<String> list2 = new ArrayList<>(List.of("a", "B", "C", "d"));
System.out.println(list2.retainAll(list1)); // 是否存在交集,true
System.out.println(list2); // 交集的结果:["B", "C"]那你可能会产生疑问,找交集和批量删除有什么关系,为啥可以封装成一个方法?
其实本质上差别不大,一个是删除给定集合c在此集合的所有元素(本质上就是删除交集部分),另一个则是仅保留交集部分,通过封装 batchRemove 实现批量删除或保留元素的逻辑,这是出于性能优化和代码复用的考虑,只需要O(n)的时间复杂度就能实现遍历、筛选和覆盖,这提升了性能;且由于是直接在原数组 elementData上操作,这避免了创建新数组,可以减少内存分配和拷贝开销。
知道了好处,那来聊聊具体是怎么做的:
先来看批量删除元素。
ArrayList<String> list1 = new ArrayList<>(List.of("A", "B", "C", "D"));
ArrayList<String> list2 = new ArrayList<>(List.of( "B", "C"));
System.out.println(list1.removeAll(list2));
System.out.println(list1);这里用了一种双指针的做法,r是读指针,w是写指针,删除时complement恒为false。读指针r依次遍历对象数组elementData,通过contains方法依次比较当前指针所在的元素是否在目标集合c中,如果没有(contains为false),那就说明这个元素不需要被删除,就直接把元素按顺序放置。以元素“A”为例,此时是第1轮循环,r=0; w=0,所以是elementData[0] = elementData[0],即元素“A”的位置不变,执行完后elementData数组的内容是["A", "B", "C", "D"];
后续来到了元素“B”,由于“B”在入参
集合c中,也在当前集合elementData中,且complement为false,意思是这个元素不要,读指针r继续往后走r++,写指针w不变,后续的元素“C”也是同理,这两轮循环执行完后elementData数组的内容还是["A", "B", "C", "D"];
接着来到元素“D”,由于“D”不在入参集合c中,此时contains为false同时if语句的结果为true,意思是这个元素我们需要,读指针r往后走r++,然后根据写指针w写入数据:elementData[1] = elementData[3],此时elementData数组的内容是["A", "D", "C", "D"],接着写指针w往后走w++;后续由于r=size所以try代码块结束,得到elementData数组["A", "D", "C", "D"]。

这样一处理,乍一看好像不是我们要的结果,但如果将数组从写指针w处截断,不就正好是我们要的删除后的元素数组["A", "D"]了么?同理如果是retainAll方法,那得到的结果就是["B", "C", "C", "D"],从写指针w=2处截断,也正好是交集结果["B", "C"]。
实际上finally代码块中正是要做这件事,可以看到它分成了两个部分:
第一部分检查读指针r是否不等于当前列表元素个数size,这种情况一般不会发生,算是异常安全处理机制,目的是确保即使遍历过程中抛出异常,剩余未处理的元素也能被正确复制到数组的合适位置,保证数据一致性。里面的内容也就两句话,复制元素,然后更新写指针w的位置为列表长度size减去之前读到的位置r。
然后来看第二个if代码块,这里的意思是如果写指针w并没有将列表内容全部写一遍,只是写了一部分时,比如上面的例子中,列表长度是4,但只写了2个元素,就应该将多余的元素删掉,这里的表现形式就是将数组中对应的下标置为null。for循环部分执行结束后elementData的内容就成了["A", "D", null, null],此时只需要将列表长度size和操作数modCount一更新,那批量删除就完成了。

简单画了张流程:
7、indexOf
找出指定的元素第一次出现的列表下标。
7.1 indexOf(Object o)
这个方法其实挺简单的,其核心是根据元素的equals方法确定是否一样,如果找的是null,则直接使用==运算符:
7.2 lastIndexOf(Object o)
几乎和indexOf一模一样,除了遍历的方向不同:
8、sort
列表的排序底层本质上是基于数组的排序来的,而如何排序取决于我们传入的排序函数c的结果: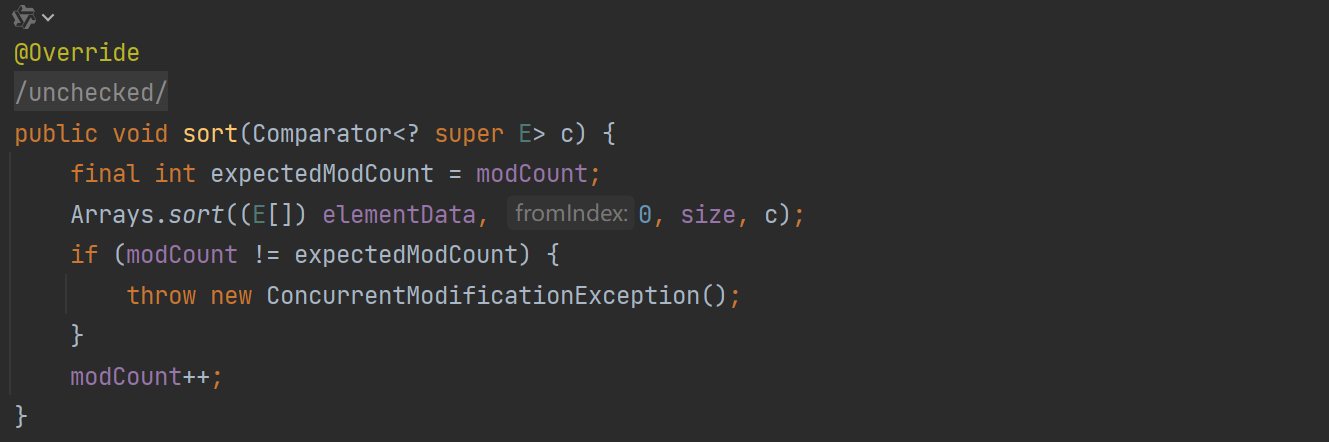
可以看到其核心就是数组工具类提供的Arrays.sort方法,这一坨的内容还挺多的,后面学到了单独开新坑讲。
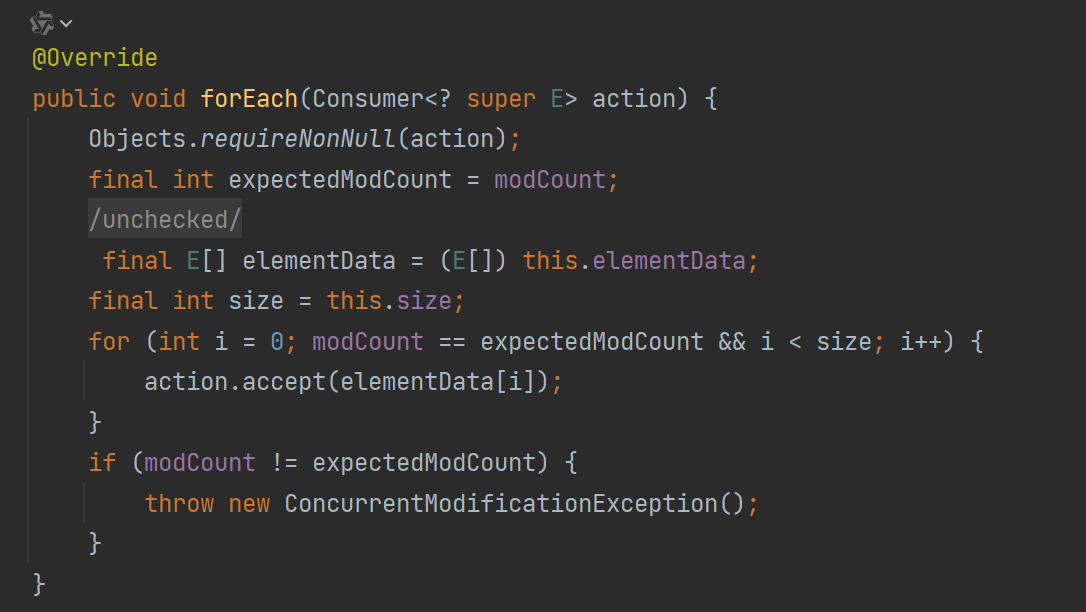
9、forEach
forEach方法没什么好说的,用法上就是传入一个函数,可以在参数上拿到当前循环的元素,做法上就是把循环封装在了forEach方法的内部,然后使用action.accept执行我们自己的函数,传入当前次循环的元素elementData[i]。
10、contains
这个方法的作用是检查给定元素o是否在指定集合中。源码上这个方法非常简单,就是把indexOf做了一下二次封装,实际就一行代码: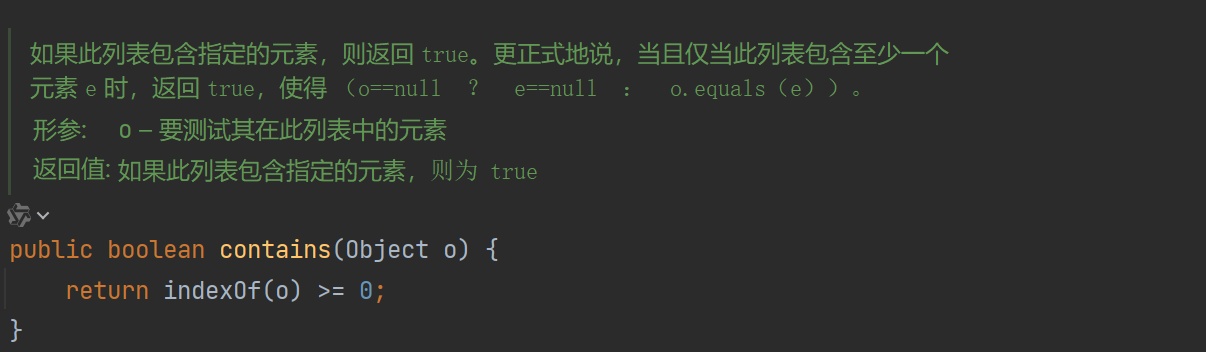
11、isEmpty
这个方法我也经常用,说实话在我第一次知道ArrayList的底层是基于数组实现时我还在疑惑,这玩意儿咋确定我是往列表中add了null,还是这个地方本来就是null,结果看了源码发现就一句话,判断了下size是不是0,看了源码才知道有些东西简单才是好:

12、toString
toString方法,每个人都用过,原理上也不复杂,就懒的画图了,大体流程就是字符串拼拼拼: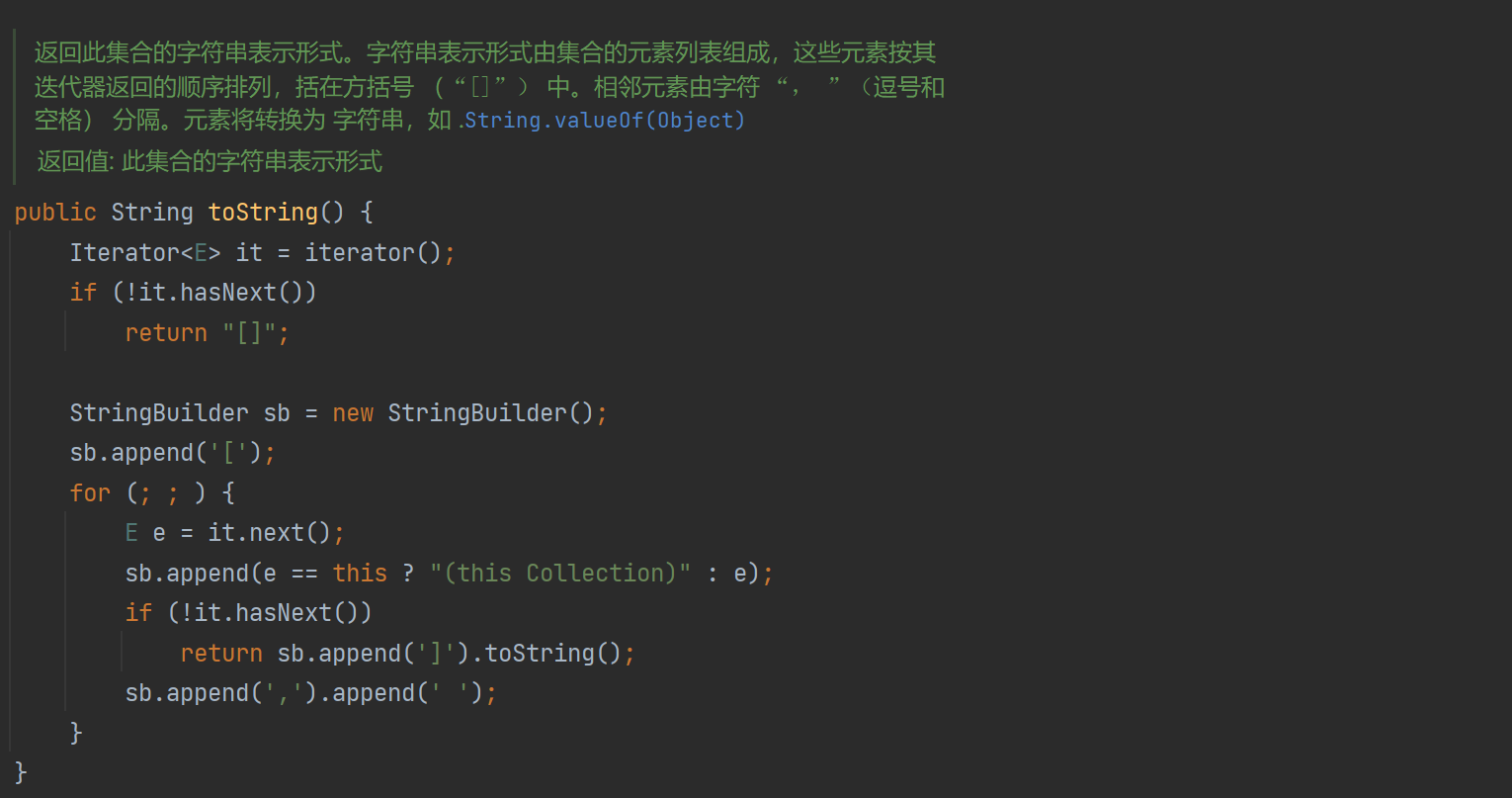
结语
ok,以上这些就是作者常用的一些方法和对它们的理解,在此记录一下避免遗忘,总的来说ArrayList在结构上还是比较简单的,后续可能还会开新坑聊LinkedList、HashMap这些东西,但那些都是后话了,以后再说吧。
